With LM Studio, you can run local AI models (LLMs) on your own computer, without relying on cloud services like OpenAI. In this guide, you'll learn how to install LM Studio, download an LLM, test it, and how to start the API server to use the model in your own applications.
1. Download and Install LM Studio
LM Studio is distributed as an AppImage, a standalone executable file. Follow these steps to install it:
- Download LM Studio
- Go to lmstudio.ai and download the Linux AppImage.
- Save the file in a directory such as
~/Applications/.
- Make the file executable
Open a terminal and run the following command:chmod +x ~/Applications/LM-Studio-*.AppImage - Start LM Studio
~/Applications/LM-Studio-*.AppImageYou can now use LM Studio, but let's also ensure it appears in your application menu.
2. Add LM Studio to the Applications Menu
Create a .desktop file so that LM Studio appears in your application menu:
nano ~/.local/share/applications/LM-Studio.desktop
Paste this content and adjust the path:
[Desktop Entry]
Type=Application
Name=LM Studio
Exec=/home/user/Applications/LM-Studio-0.3.8-4-x64.AppImage --no-sandbox
Icon=/home/user/Applications/lmstudio-icon.png
Terminal=false
Categories=Development;AI;
Save with CTRL+O, close with CTRL+X, and update the menu:
update-desktop-database ~/.local/share/applications
You can now open LM Studio from the application menu! 
3. Download a Local LLM Model
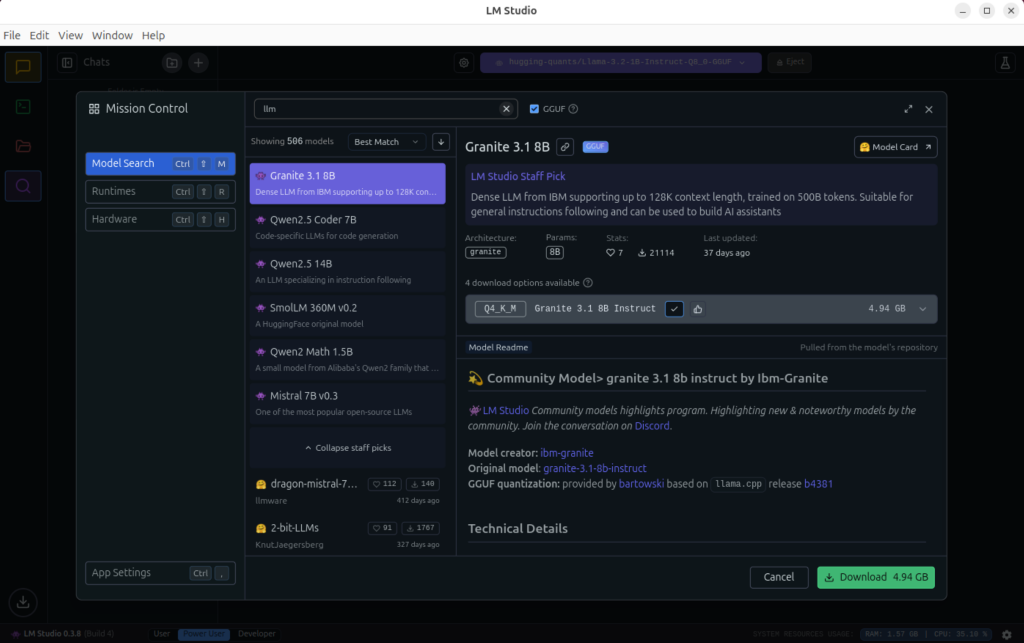
- Open LM Studio and go to Model Search.
- Search for Llama 3.2 1B Instruct (lightweight and beginner-friendly).
- Select a Q4_K_M or Q8_0 quantization (lower bit values use less RAM).
- Wait for the download to complete.
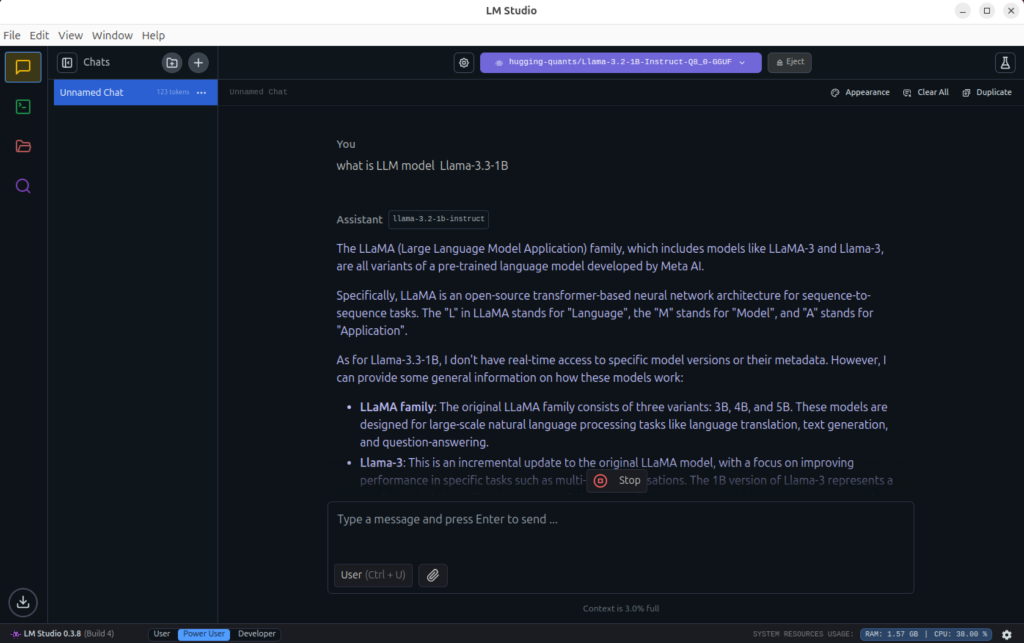
4. Test if the Model Works
- Go to Chats in LM Studio.
- Start a new chat and select the loaded model.
- Type questions like:
"What is the capital of France?" "Explain quantum mechanics in simple terms." "What is LLM model Llama-3.3-1B?" - If the model responds, everything is working!
5. Start the LLM API Server for Use in Your Own App
Want to integrate LM Studio into your Python app or chatbot? Start the local server:
- Open LM Studio and enable "Developer mode".
- Click "Start Server" (the server will run at
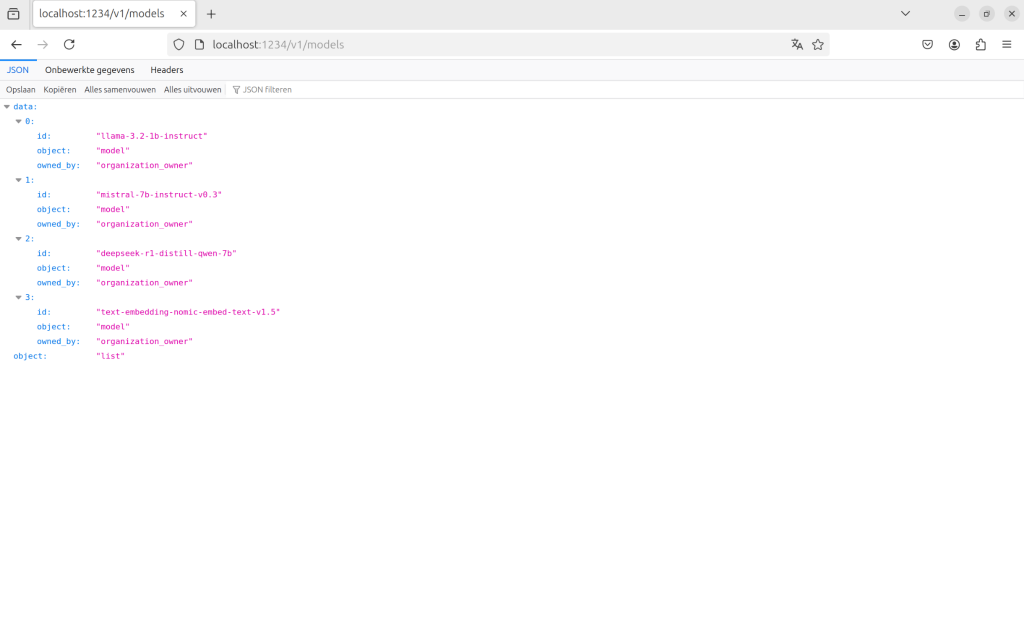
http://127.0.0.1:1234). - Test if it's working:
curl http://127.0.0.1:1234/v1/models

6. Example: Using LLM in a Python App
import requests
url = "http://127.0.0.1:1234/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "llama-3.2-1b-instruct",
"messages": [{"role": "user", "content": "What is the capital of France?"}]
}
response = requests.post(url, json=data, headers=headers)
print(response.json())
To send a JSON-formatted POST request in PHP to interact with LM Studio's API, you can utilize PHP's cURL library. Here's how you can structure your code:
<?php
// API endpoint URL
$url = 'http://127.0.0.1:1234/v1/chat/completions';
// Data to be sent in the POST request
$data = [
'model' => 'llama-3.2-1b-instruct',
'messages' => [
['role' => 'user', 'content' => 'Wat is de hoofdstad van Frankrijk?']
]
];
// Initialize cURL session
$ch = curl_init($url);
// Encode data to JSON format
$payload = json_encode($data);
// Set cURL options
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $payload);
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Content-Type: application/json',
'Content-Length: ' . strlen($payload)
]);
// Execute cURL request
$response = curl_exec($ch);
// Check for errors
if ($response === false) {
$error = curl_error($ch);
curl_close($ch);
die('cURL Error: ' . $error);
}
// Close cURL session
curl_close($ch);
// Decode and display the response
$result = json_decode($response, true);
print_r($result);
?>This sends a query to the local LLM and prints the response.
7. Minimum System Requirements for LM Studio
Want to run a local LLM? Here are the minimum and recommended specifications:
| Component | Minimum Specs | Recommended Specs |
|---|---|---|
| CPU | Intel Core i5 (AVX2) | Intel i7/i9 or AMD Ryzen 7/9 |
| RAM | 8 GB | 16-32 GB (for larger models) |
| Storage | 10 GB free space | 50 GB+ (for multiple models) |
| GPU | Not required | NVIDIA GPU with CUDA for faster performance |
The more powerful your CPU/GPU, the faster the LLM will respond. A GPU like an NVIDIA RTX 3060+ can significantly speed up the process.
Conclusion
With LM Studio, you can run, test, and use local AI models without depending on cloud services. Whether you're creating a chatbot, AI assistant, or embedded LLM, this is a great way to run AI locally. 
 Simple script to use ChatGPT on your own files with LangChain
Simple script to use ChatGPT on your own files with LangChain